
第3章 指数构造方法篇
在过去的三十年中,一些专业组织、科研机构以及研究学者以国家、区域、产业、企业等为对象建立了不同层面、不同形式的创新评估体系。
需要指出的是,这些基于科学调查和专家咨询的评估方法普遍存在以下一些问题:
(1)目前绝大多数的创新指数评估在指标的选取与权重的生成上高度依赖于专家的主观判断。此外,当需要评估的样本企业数量非常庞大时,评估者是否有足够的时间和精力去准确地评估也是实践上会面临的挑战;
(2)在现有的企业创新评估方法中,大多把关注点放在研发、专利活动等基于技术形式的创新,而对商业模式创新等创新形式较为忽略;
(3)现有评估方法对创新能力或指数测度的基本思路是先定义,再从逻辑出发构建指数所包含的维度。然而,考虑到创新本身就是一个较为综合而复杂的活动,刻画创新活动的不同指标不可避免地存在着信息部分重叠等问题。
为此,我们构建的中国上市公司创新指数评估方法,目标在于解决上述问题:
(1)我们希望所构建的评估方法不依赖于个人的主观判断;
(2)非技术类创新这类对公司竞争力和绩效常常也很重要的因素会被纳入评估之中;
(3)我们所建立的评估方法具有较低的评估成本,并且可以在较长的时期内追踪我们所考察的企业样本(上市公司);
(4)对于创新缺乏广泛被认可的概念及维度的问题,我们采用信息抽取思想来解决。这意味着我们关注的是创新能力中被实现、体现出来的部分,也就是其对公司绩效的贡献。我们相信创新的意义在于对价值创造的贡献,所以我们选取了EVA作为公司绩效的反映指标。
我们所构造的上市公司创新指数包括了创新势力(innovation strength)和创新效率(innovation efficiency)两个维度。
在创新势力的评估上我们采用的基础数据包括:
(1)研发投入规模:直接反映了公司在研发上财务资源投入;
(2)研发人员规模:背后反映了公司隐性知识的数量;
(3)专利规模数据:因为专利可以被理解为企业所拥有的显性知识;
(4)平均销售利润率:一家公司创新势力很强的话,那么它在市场中将具有足够的定价能力,其反映为公司在平均销售利润率上会具有优势。
用于评估创新效率的基础数据则包括:
(1)研发强度指标:研发投入强度以及研发人员强度二者的算数平均;
(2)技术效率:通常,企业在资源利用达到最理想的情况下应该得到一个最大的潜在产出水平。然而真实产出水平往往由于资源没有得到充分利用,而低于上述理想状态(即潜在产出水平)。偏离的程度则代表了企业技术效率的高低,技术效率越高,应该越接近在理论上能达到的最大产出水平。我们衡量了在产品意义上和知识意义上两种情形下的技术效率。
(3)商业模式新颖性:我们评估了企业的商业模式偏离其所在行业平均状态的程度。这个偏离程度越大,一定程度上反映这个公司商业模式的独特性越高。
一、基础指标的数据来源与测度
(1)研发投入
研发投入数据主要来自wind数据库的“研发费用”字段;缺失的数据从对应企业的年报中进行补充。
(2)研发人员
研发人员数量主要来自wind数据库中“技术人员人数”字段;缺失的数据从对应企业的年报中进行补充。
(3)专利数量
专利数量数据全部来自国家知识产权局的专利检索系统,以上市公司为申请人,查询公开(公告)日介于2020年1月1日至2020年12月31日之间的专利总量。
(4)销售利润率
销售利润率(ROS)=税后净利润/销售额;其中,税后净利润数据和销售额数据分别来自国泰安数据库(CSMAR)的“净利润”和“营业收入”字段。
(5)研发强度
研发强度的测度有两类,分别为“研发强度_费用(研发投入/营业收入)”和“研发强度_人员(研发人员/员工总数)”。本研究所用的研发强度为研发强度_费用和研发强度_人员二者的均值,计算公式如下:

公式 3.1
研发投入、研发人员和营业收入的数据来源如前所示,员工总数数据来自国泰安数据库(CSMAR)的“员工人数”字段。
(6)技术效率
技术效率是衡量企业生产经营效率的重要指标。技术效率的计算主要利用stata 14.0软件中提供的随机前沿分析(SFA)模块,估算超越对数生产函数,具体模型如下所示:
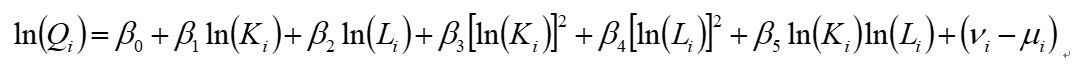
公式3.2
其中,Qi、Ki、Li分别代表了增加值、固定资产净额以及员工总数。
增加值的计算方式依据收入法,其计算公式如下:
公司增加值=应付职工薪酬+应交税费+应付利息+固定资产折旧+资产减值损失+公允价值变动收益+投资收益+汇兑收益+营业利润。
员工总数数据来源如前所示,计算增加值所需的数据和固定资产净额数据均来自国泰安数据库(CSMAR)。
(7)商业模式新颖性
为了测量焦点企业同行业内其他企业商业模式平均水平的差异性(即新颖程度),我们构造了一个多维矢量,包含前五名供应商占比、前五名客户占比、营业周期、流动资产与收入比、销售费用率、非制造业占收入比共六个维度。计算公式如下:
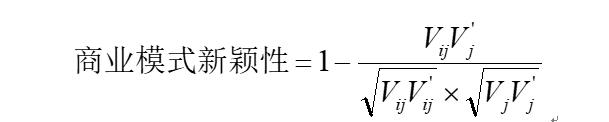
公式3.3
其中,Vij为焦点企业的矢量,Vj为行业平均水平的矢量。
二、评估权重生成
权重的确定一般有两种方式。一种是利用德尔菲法让专家来确定每个指标赋予的权重,但是这种方法主观性较强。本研究采用统计方法,依靠二手数据更加客观地计算出各个指标的权重,以保证测度的客观性。本研究以绩效为因变量,以创新指标为自变量,估计各个指标的权重。具体做法如下:
(1)选择因变量
EVA(经济增加值)是衡量企业为社会创造经济价值的指标。作为公司业绩的度量指标,与其他度量指标的不同之处在于,EVA考虑了带来企业利润的所有资金成本。在这个意义上,EVA更加真实地揭示了上市公司的经济业绩,可以帮助企业判断是否在当期真正为股东创造了价值。EVA数据来自国泰安数据库(CSMAR)。
(2)自变量及其无量纲化
自变量包括研发费用、技术人员人数、专利总数、销售利润率、研发强度、商业模式新颖性、技术效率等7个变量。
由于自变量的量纲不统一,各个行业之间差别很大,这样会增大估计的误差。因此,为了使得回归中的跨行业存在可比性,我们首先将自变量中的各个指标剔除行业均值,从而排除行业带来的差异。然后按照以下公式(公式3.4),将所有自变量的取值统一在0-10范围内,便于模型的回归。
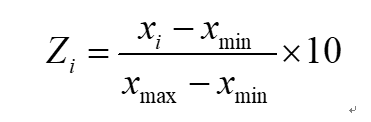
公式3.4
其中,xi表示自变量x的第i个观测的取值,xmax和xmin分别表示自变量x的最大值和最小值,Zi表示xi无量纲化后的取值。
(3)回归分析与权重计算
因变量为2019年的EVA,自变量为2018年无量纲化之后的研发费用、技术人员人数、专利总数、销售利润率、研发强度、商业模式新颖性、技术效率,控制变量为2018年的员工总数和企业年龄。本指数采用OLS进行回归。第1个模型为基础模型,只放入控制变量。第2到第8个模型,每个模型都在前一个模型的基础上新增一个自变量,最终得到8个回归结果。因为回归模型 衡量了该模型中自变量和控制变量对因变量的解释程度,而每新增一个自变量进入回归模型都会导致解释程度的增大(或者不变),因此,新增一个自变量所导致的回归模型
衡量了该模型中自变量和控制变量对因变量的解释程度,而每新增一个自变量进入回归模型都会导致解释程度的增大(或者不变),因此,新增一个自变量所导致的回归模型 的增加值代表了该自变量对因变量的贡献。每个自变量权重的计算公式如下:
的增加值代表了该自变量对因变量的贡献。每个自变量权重的计算公式如下:
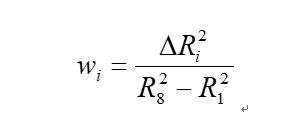
公式3.5
其中,Wi表示第i个模型在第i-1个模型的基础上新增的自变量的权重。
值得注意的是,自变量放入模型的顺序会影响该自变量的权重。为了消除这一问题,本研究穷举全部7个自变量可能进入模型的顺序,共计35280种可能的组合,对每种组合进行回归,然后计算各个自变量的权重,然后对每个自变量的权重求均值作为该自变量最终的权重。根据上述方式,我们可以算出每个指标的权重。
(4)得分计算
创新指数得分分为“创新势力”和“创新效率”两个维度。其中,“创新势力”得分的计算基于规模型指标,“创新效率”得分的计算则基于效率型指标。在计算创新指数得分时,我们对每个指标进行无量纲化处理,且无量纲化不预先去除行业均值。
创新指数得分的计算公式如下:
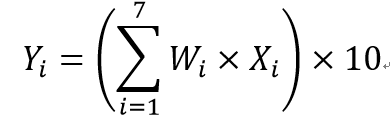
公式3.6
其中,X1~X7分别是无量纲化之后的研发投入、研发人员、专利数量、销售利润率、研发强度、商业模式新颖性和技术效率,Wi表示第i个变量的权重。为了将创新指数得分的取值范围变为0~100,
本研究在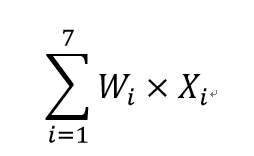 的基础上乘以10。
的基础上乘以10。
创新势力得分的计算公式如下:
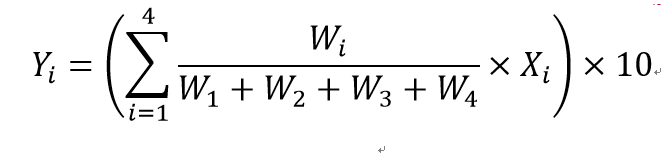
公式3.7
其中,X1~X4分别是无量纲化之后的研发费用、技术人员人数、专利总数和销售利润率。为了将创新势力得分的取值范围变为0~100,
本研究在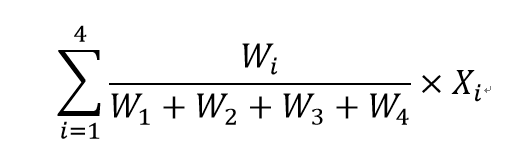 的基础上乘以10。
的基础上乘以10。
创新效率得分的计算公式如下:
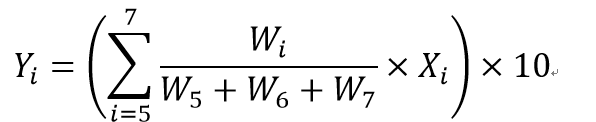
公式3.8
其中,X5~X7分别是无量纲化之后的研发强度、商业模式新颖性和技术效率。为了将创新势力得分的取值范围变为0~100,
本研究在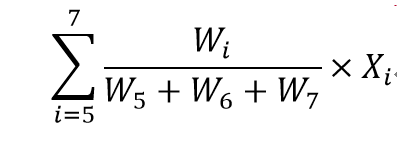 的基础上乘以10。
的基础上乘以10。